📍 Processing PDF Files
Parsio allows you to import, parse, and export data from PDF files in several ways.
The best approach depends on where your PDFs come from and what kind of data you want to extract.
Importing PDF files to Parsio
Parsio offers several ways to import PDF files for processing:
Email attachments
Forward emails with PDF attachments to your Parsio mailbox.
This is the easiest and most common approach and can be fully automated using email auto-forwarding rules.
Manual upload
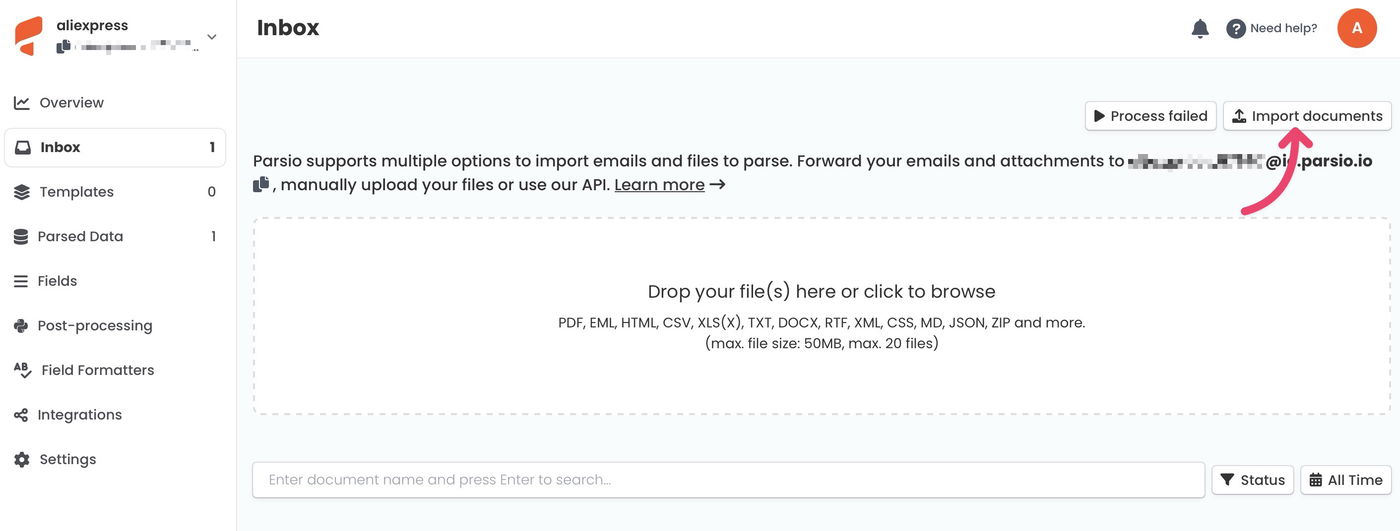
Upload one or more PDF files directly from your computer.
Open the Inbox page and click Import documents.
Download PDFs from external links (template-based parser only)

Sometimes emails contain links to downloadable PDF files instead of attachments.
In this case, you can use the Downloadable Document field type:
Create a template based on the parent email
Switch to the RAW tab
Locate the PDF URL and create a field from it
The PDF file must be publicly accessible. Links requiring login or authentication are not supported.
API upload
You can also import PDF files programmatically using the Parsio API.
Parsing PDF files
Parsio provides four parsing engines that can process PDF files.
Choosing the right one depends on the document structure and your use case.
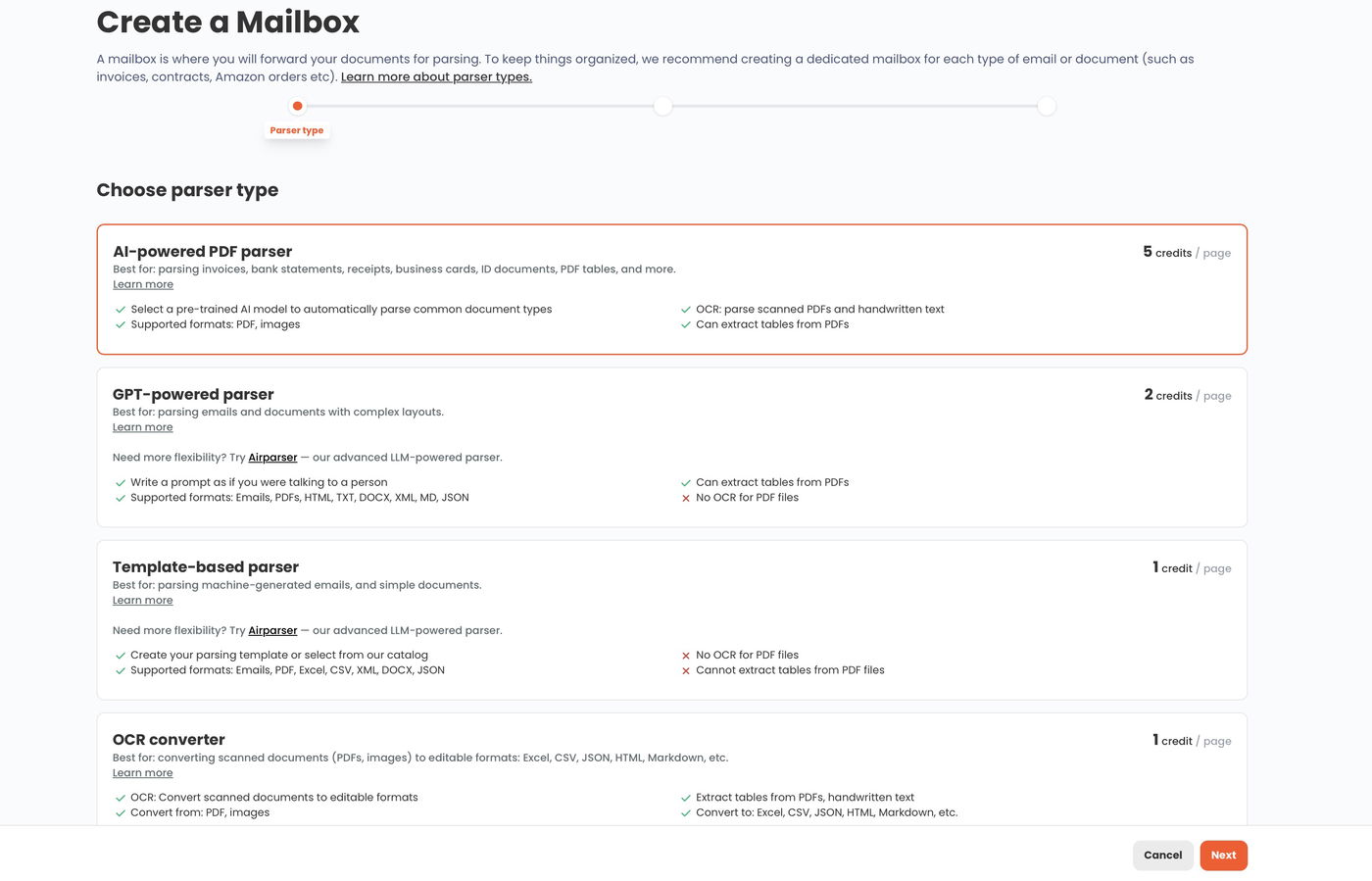
AI-powered parser (pre-trained models) — for common document types
This parser uses pre-trained AI models to extract data from common document types such as:
Invoices
Receipts
Bank statements
PDF Tables
It supports both:
Text-based PDFs
Scanned PDFs and images (OCR included)
In many cases, this is the best choice for PDF processing.
GPT-powered parser — flexible and layout-agnostic
The GPT-powered parser is ideal for:
PDFs with changing or inconsistent layouts
Semi-structured or unstructured documents
Custom or non-standard PDF formats
You list the fields you want to extract in a text prompt, and Parsio handles the rest. It supports both text-based and scanned PDFs.
Template-based parser — limited PDF support
The template-based parser can process simple, text-based (searchable) PDFs with a fixed structure.
Limitations:
Does not support scanned PDFs or images
Best suited for machine-generated emails or documents with a consistent layout
When using this parser, PDF files are first converted to text, which may look different from the original document.
OCR converter — convert PDFs to editable formats
Use the OCR converter when you don’t need structured data extraction, but only want to convert scanned PDFs or images into editable formats such as:
Text
Tables
Word, Excel, or CSV files
This tool is designed for conversion, not parsing or data extraction.
Exporting the parsed data
Once your PDFs are processed, you can export the extracted data in real time using:
CRM systems or databases
Integration platforms such as Zapier, Make, n8n, or Pabbly Connect
Export options are the same for all document types (emails and files). For more details, see the Data Export & Integrations section.
Need help choosing the right parser?
If you’re unsure which parser to use or need help setting things up, contact our support team via live chat or email us at support@parsio.io.